主要内容来自 DDIA 第十一章 流处理系统,还有自己关于 Golang 流计算的一些调研
背景 🔗
计算服务可按以下方式分为三类:
-
在线服务:当收到请求时,服务尽可能快的处理并且发挥一个响应,如常见 Web 服务。
-
批处理(离线)系统:一次性接收并处理大量的数据,往往需要执行比较长的时间(几分钟到几天),所以用户不会同步等待返回结果,这种作业一般定期执行。最常见是 MapReduce
-
流处理(近实时)系统:流处理介于在线与离线之间。批处理输入是有界的,而流处理的输入是无界的。当有新事件到达时,流系统就会处理。比较流行的流处理系统有 Storm, Spark,Flink
今天我们来简要介绍下流式处理,尤其是其中流分析相关的部分
流式处理的适用场景 🔗
一般用于实时监控报警
- 复杂事件处理,允许指定规则,从而在流中搜索特定模式的事件。使用像 SQL 这样的声明式语言来描述应该检验的事件模型
- 流分析,其与复杂事件处理之间的界限有些模糊。主要差别在其不关心特定序列,更多面向大量数据的累计效果与统计指标,例如,测量某种事件的速率,一段时间内某个值的平均值等
- 维护物化视图,使用数据库更改流(如 binlog 流)来保持派生数据系统
- …
流处理系统一些难点 🔗
1. 时间问题 🔗
流处理需要和时间打交道,尤其在用于流分析时,如 “最近 5 分钟的平均值”,这个 “最后 5 分钟” 的定义其实非常模糊,处理起来非常麻烦。在流处理框架,一般使用两种时间:
- 事件处理时间,流处理框架处理这个事件时的本地系统时钟
- 事件发生时间,事件自己记录的发生时间
事件处理时间一般要比事件发生时间延迟一些。例如 A 事件发生 00:00, 经过消息队列,到达流处理系统时处理时间为 00:03 了。
时间窗口该使用哪个定义?这时候就需要使用者根据自己系统的特点和使用目的做一些取舍了。
-
使用事件处理时间,这种方式的优点是简单,并且在发生时间与处理时间之间延迟不大的情况下,效果非常好。
-
使用事件发生时间,可以使处理过程是确定性的:基于同一个输入,再次运行相同的处理过程可以得到相同的处理结果。这样能够支持流批一体,并且能够处理发生时间与处理时间之间延迟很大的情况。
使用事件发生时间的缺点是其实现比较复杂,例如无法确定什么时候能够收到特定窗口内的所有事件。一般有两种处理方式:
- 忽略滞后的事件
- 发布一个更正
2. 窗口类型 🔗
流分析一般需要在一个时间窗口内做聚合分析,例如一段时间内的计算,平均值。一般窗口类型可分为以下三类。
-
滚动窗口:滚动窗口下窗口之间不重叠,且窗口长度是固定的
-
滑动窗口:滑动窗口以一个步长(Slide)不断向前滑动,窗口的长度固定
-
会话窗口:没有固定的持续时间,将一组用户在时间上紧密相关的所有事件分组在一起。一旦用户在一段时间内处于非活动状态,窗口结束

窗口意义在于聚合,也不局限于上述几种,用户选择满足自己需求的窗口类型/自定义窗口都可,
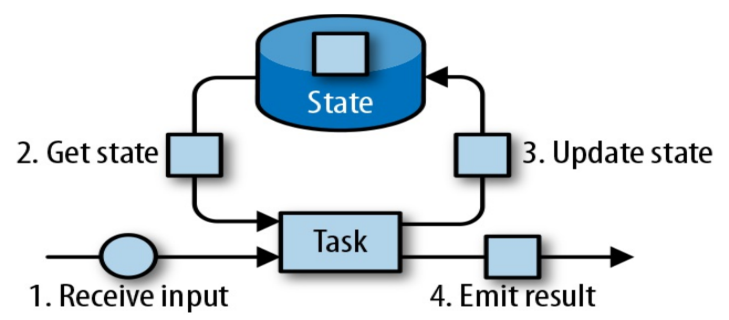
3. 有状态计算 🔗
有状态的计算是流处理框架要实现的重要功能,因为复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面罗列了几个有状态计算的潜在场景:
- 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入数据来判断去重。
- 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
一般需要在一个第三方存储中统一维护状态,如 Flink 中的 RockDB
流处理框架 🔗
现在比较流行的是 Apache Storm,Spark Streaming,和 Apache Flink
使用流程以 Flink 为例:
- 搭建 Flink 集群
- 编写 Java 代码:流的处理逻辑
- Flink 服务运行打包后的 Jar 包程序
可以看到使用起来是比较重的
有没有能在应用程序中能够简单进行一些流分析的工具?
Go-zero 流数据处理工具 fx:只是类似于 java stream 包的东西, 对无界数据处理比较难
go-stream: 无状态计算支持不错,并且实现了各种窗口类型了,具有一部分流处理框架的操作。但是其有状态计算的状态维护在单机内存,不适合分布式架构。并且其成熟度不高。