本文主要内容来自于《数据密集型应用系统设计》 第四章,推荐大家看原作
背景 🔗
在程序中,数据有两种不同的表示形式
-
在内存中的数据结构: 对象,结构体,列表,数组,散列表,树等。
-
如果要把内存中的数据结构保存到文件,或通过网络发送,则需要转换成字节序列(如 JSON )
两种不同表示的数据之间经常需要进行转换,从内存中数据结构转成字节序列成为 编码(encode)、序列化(serialization) 或 编组(marshalling)。反过来被称为 解码(Decoding) 、 **反序列化(deserialization)**或者 反编组( unmarshalling)
数据编码与演化 🔗
1. 语言特定的格式 🔗
首先比较常见的是各个编程语言内置对序列化的实现。例如 Python 中的 pickle、 Java 中的 java.io.Serializable 、Golang 中的 gob…
但除非临时尝试中,我们一般不会使用它们。这是由于:
- 这类编码通常与特定的编程语言深度绑定,其他语言很难读取这种数据,很难将系统与其他组织的系统(可能用的是不同的语言)进行集成
- 为了恢复相同对象类型的数据,解码过程需要实例化任意类的能力,这通常是安全问题的一个来源
- 在这些库中,数据版本控制通常是事后才考虑的。因为它们旨在快速简便地对数据进行编码,所以往往忽略了前向后向兼容性带来的麻烦问题
- 效率(编码或解码所花费的CPU时间,以及编码结构的大小)往往也是事后才考虑的。 例如,Java的内置序列化由于其糟糕的性能和臃肿的编码而臭名昭着
2. JSON、XML 文本格式编码 🔗
现在比较常用的 JSON、XML 两种文本格式编码,其最大优点的是可以被多种编程语言读写, CSV 是另一种流行的与语言无关的格式,但其其功能相对较弱。下面是内存中的一个对象被编码成 JSON 格式后的示例,使用文本格式编码,不仅可以被多种编程语言解码(decoding),甚至连我们人类都能直接阅读理解其意思。
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
JSON、XML 得到了广泛的应用,但也有不少问题。例如 XML 格式的复杂与冗长。JSON 的流行则主要源于(通过成为JavaScript的一个子集)Web浏览器的内置支持,以及相对于XML的简单性。下面列数了它们的一些问题
- 数值(numbers) 的编码多有歧义之处。XML 和 CSV 不能区分数字和字符串(除非引用一个外部模式)。 JSON虽然区分字符串与数值,但不区分整数和浮点数,而且不能指定精度,导致 JSON 不能表示 int64 中特别大的数值
- JSON 和 XML 对 Unicode 字符串(即人类可读的文本)有很好的支持,但是它们不支持二进制数据。人们通过使用 Base64 将二进制数据编码为文本来绕过此限制。其特有的模式标识着这个值应当被解释为 Base64 编码的二进制数据。这种方案虽然管用,但比较Hacky,并且会增加三分之一的数据大小。
- XML 和 JSON 都有可选的模式支持。这些模式语言相当强大,所以学习和实现起来都相当复杂。 XML模式的使用相当普遍,但许多基于 JSON 的工具才不会去折腾模式。对数据的正确解读(例如区分数值与二进制串)取决于模式中的信息,因此不使用XML/JSON模式的应用程序可能需要对相应的编码/解码逻辑进行硬编码
- 文本格式性能还可以待提升,例如数字 12345678901234567890 在文本格式编码中需要 20 个字节
3. 二进制编码 🔗
二进制编码对文本格式的做了一些性能方面的提升,大量二进制编码版本 JSON(MessagePack,BSON,BJSON,UBJSON,BISON和Smile 等) 和 XML(例如WBXML和Fast Infoset)的出现。这些格式已经在各种各样的领域中采用,像 BSON 在 MangoDB 中被使用,但是没有一个能像文本版 JSON 和 XML 那样被广泛采用。
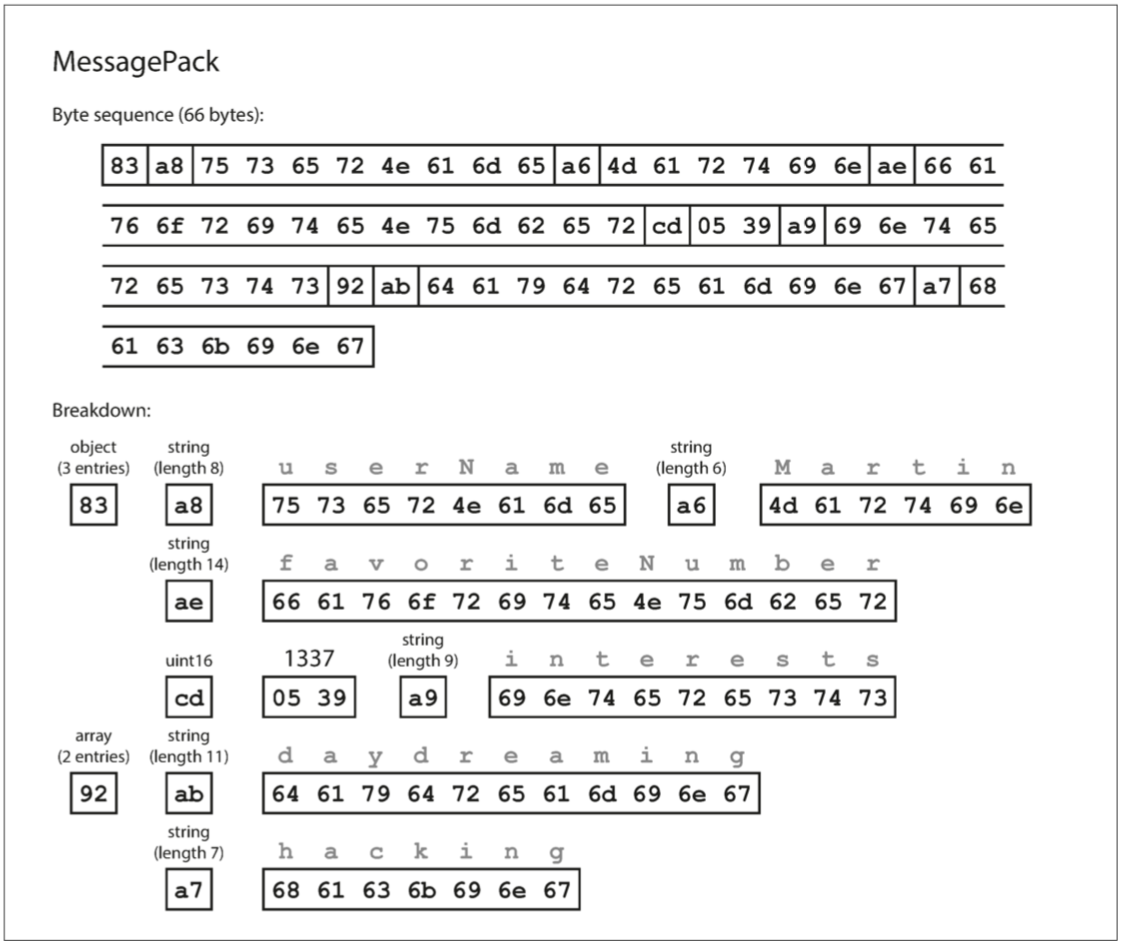
我们来看一个 MessagePack 的例子,它是一个 JSON 的二进制编码。它对上述例子的 JSON 文档 进行编码,则得到的字节序列如下图所示。二进制编码长度为 66 个字节,仅略小于文本 JSON 编码所取的 81 个字节(删除了空白)。主要的不同点:
-
数据类型与其边界,JSON 使用符号标识
{},,,""等标识,MessagePack 直接使用 2 字节规定 -
数值编码格式,JSON 使用文本编码数字,二进制的数值编码格式明显压缩率更高,8 个字节能表示 int 64 范围内的数字
所有的 JSON 的二进制编码在这方面是相似的。在空间节省了一丁点(以及解析加速)是否能弥补可读性的损失,谁也说不准
4. Thrift 与Protocol Buffers 🔗
上述二进制编码是基于 JSON 的做出的一点优化,但我们看到其效果(81 B -> 66 B)还不太够
由此出现了两种更加强大二进制编码的格式,它们基于相同的原理:
- 消息中字段名过长可能会占用过多空间,可以把字段名优化掉
Protocol Buffers 最初是在 Google 开发的,Thrift 最初是在Facebook 开发的,并且在 2007~2008 年开源。 Thrift 和 Protocol Buffers 都需要一个模式(接口定义语言 IDL)来编码任何数据。如下面例子分别用 IDL 表示了上述例子中的数据格式
// thrift
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
// protobuf
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
相信各位对这两者并不陌生,其都被广泛用于各种 RPC 中。
我们来看看这两者是如何把数据压缩到极致的。Thrift有两种不同的二进制编码格式,分别称为BinaryProtocol 和 CompactProtocol。
1. Thrift BinaryProtocol 编码 🔗
使用这种格式的编码来编码上述例子中的消息只需要 59 个字节,如下图所示。
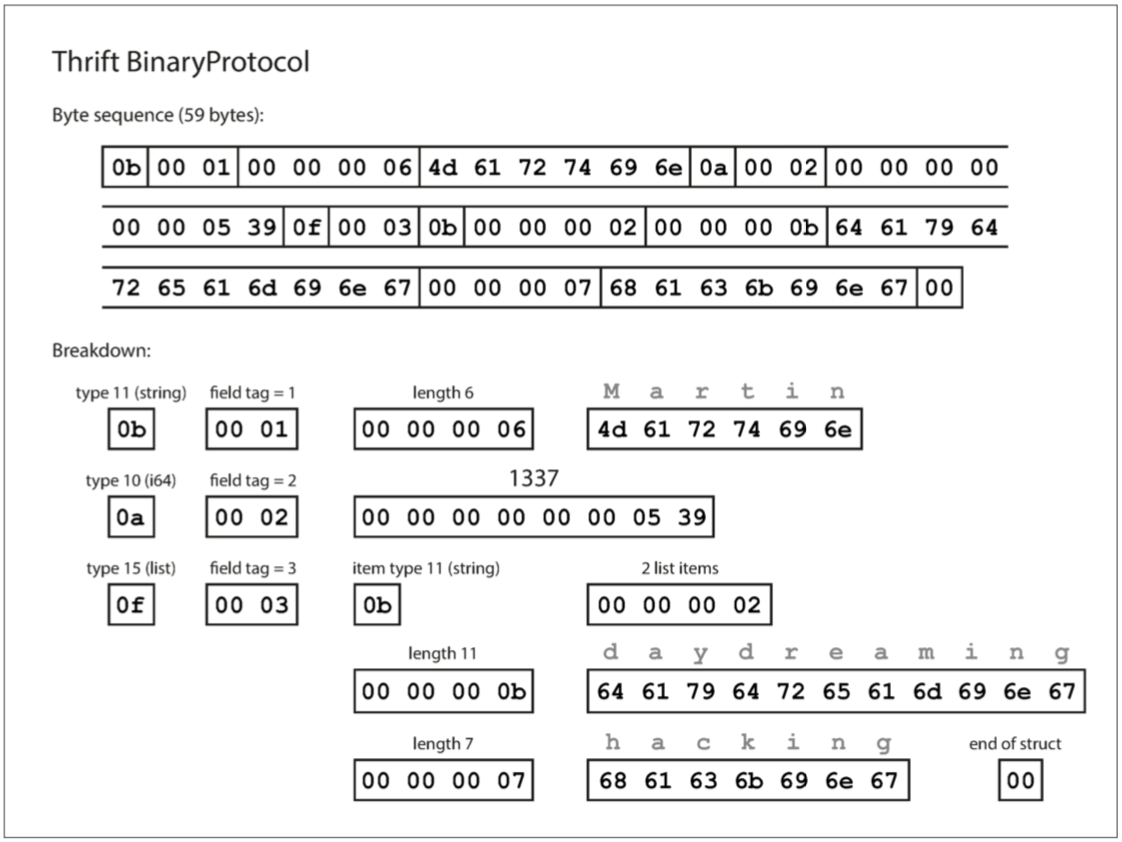
Thrift 与基于 JSON 变种二进制编码的主要优化点:
- Thrift 使用 field tag 1,2,3 代替了字段名 (userName, favoriteNumber, interests)
2. Thrift CompactProtocol 编码 🔗
其在语义上等同于 BinaryProtocol,但是如下图所示,它只将相同的信息打包成只有 34 个字节。
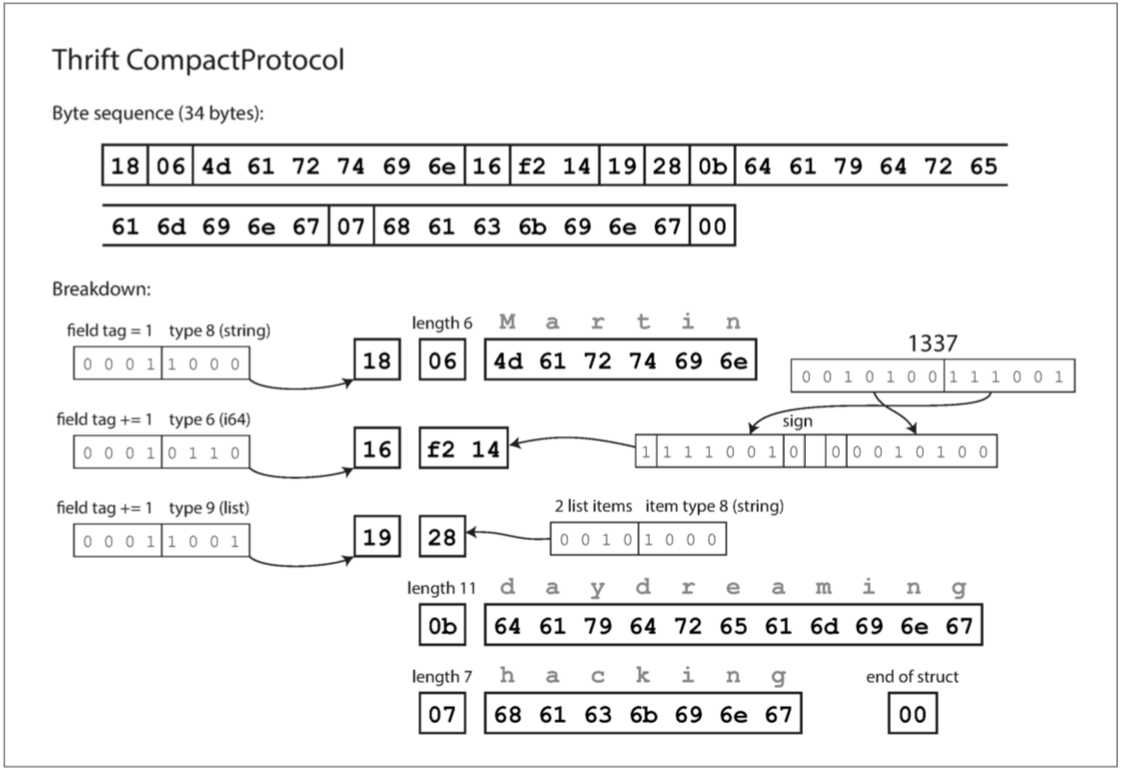
其上做了更细致的一点优化。
- 它通过将字段类型和标签号打包到单个字节中,
- 使用可变长度整数编码, 实现原理每个字节的最高位用来指示是否还有更多的字节。这意味着 -64 到 63 之间的数字 只要一个字节,-8192 和 8191之间的数字只需要用两个字节编码…
3. Protocol Buffers 编码 🔗
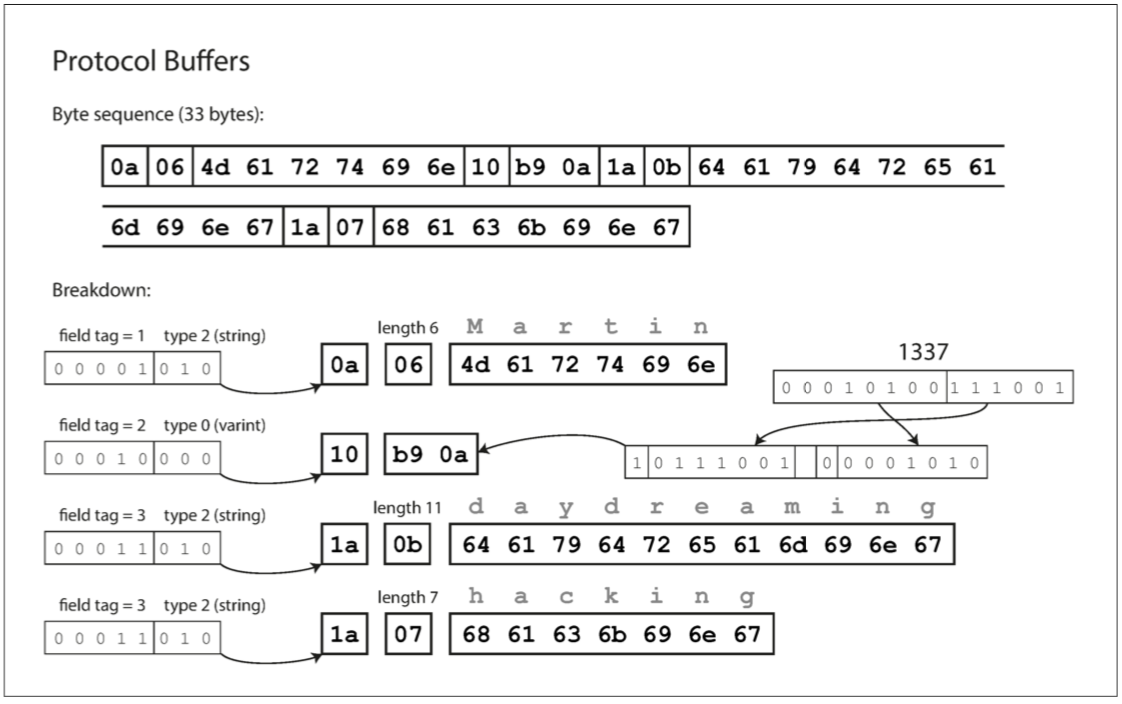
其与Thrift的 CompactProtocol 非常相似。 Protobuf 将同样的记录塞进了 33 个字节中,如下图所示。
Thrift 与 Protobuf 需要注意的一些问题 🔗
- IDL 中有
Require与optional, 怎么没有在字节编码序列中表示出来
不需要。处理方式为:
- 字段设置为
required,但未设置该字段,则所需的运行时检查将失败 - 字段设置为
optional,如果没有被设置,则不会序列化到消息结构体
- 字段标签和模式演变
- 向前兼容性:
- 字段名修改无所谓,不要去修改字段标签。
- 可以添加新的字段到架构,只要你给每个字段一个新的标签号码,旧的代码读取到新的数据会忽视新增加的字段
- 你只能删除一个可选的字段(必需字段永远不能删除),而且你不能再次使用相同的标签号码(因为你可能仍然有数据写在包含旧标签号码的地方,而该字段必须被新代码忽略)
- 向后兼容性:只要每个字段都有一个唯一的标签号码,新的代码总是可以读取旧的数据
总结 🔗
主要介绍了数据编码的演化历史,以及它们之间所做的优化。此文作为我自己阅读记录,推荐大家去看 DDIA 原作。