Raft 实现真的比较难,首先要从整体上完全理解 Raft 的运行机制就比较困难。再具体到实现上,涉及到很多个后台 goroutine(goroutine 中起 goroutine),如何加锁才能安全读取写入共享变量(一不小心还死锁),并发难以 debug,计时器的实现… 这篇文章记录下我的个人经验把,希望对其他人能有所帮助
实验前 🔗
必看 🔗
-
raft论文 leader 选举和 Log 复制部分
选看 🔗
- lec 3,4
- 课程视频 lec 6, 7
建议 🔗
-
lecture 3 讲 GFS,lecture 4 讲一个复制容错的论文。与我们要实现的 raft 的关系不大,最多算一些前置知识,建议不看。
-
建议 lab2A 与 lab2B 一起做,虽然 lab2 文档把 lab 分开为两个部分。但是我们是去对照论文实现,尤其在
RequestVote与AppendEnties两个 RPC 中,这两者混杂在一起 -
多读几遍论文与 lab2 文档,尤其是论文中的图 2, 再开始 lab…
-
论文暂时可以只阅读与 2a 2b 相关的部分
实验过程 🔗
思路分析 🔗
论文中的这图太重要了,放上来再看一下吧

在 2a,2c 实验中,我们认为:
- 所有日志都存在于内存中,持久化在 2c 考虑
- 与上层应用交互的逻辑应该是这个实验最后考虑的地方,我们先考虑实现 leader 选举,发送心跳的逻辑
三种角色 🔗
字段意义 🔗
按照论文描述和我的实际实现,我在 Raft 实例中增加了以下字段。
这些字段大多数都会被并发读写,请在访问前后加锁
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
state State // 此实例状态: Follower, Candidate, Leader
currentTerm int // 当前任期
voteFor int // 当前任期投票
logs []LogEntry // 所有日志条目
commitIndex int // for 2b,已经提交的最新日志的 index, "已经提交" == 这条日志已经被大多数 server 所接受
lastApplied int // for 2b, 已应用到的上层应用日志最新的 index,后台定时根据 commitIndex 的增加去提交
applyCh chan ApplyMsg // for 2b, 需要把已经 committed 的 log apply 到 上层应用
// for leader
nextIndex []int // 记录各个 Server 写入新 Log 的位置 index(意味着这个位置以前的日志在 leader 与 follower 完全一致)
matchIndex []int // 各个 Server 已有 Log 的与 leader 保持一致最后的位置 = nextIndex - 1
electionTimeout time.Time // 应该被不断 reset,始终比 time.Now() 小。但如果到点了,说明过期了,发起选举
}
type State int
const (
Follower State = 1
Candidate State = 2
Leader State = 3
)
type LogEntry struct {
Command interface{}
Term int
}
状态流转如下图所示(论文图 4),牢记,按照这个顺序去一一实现代码逻辑
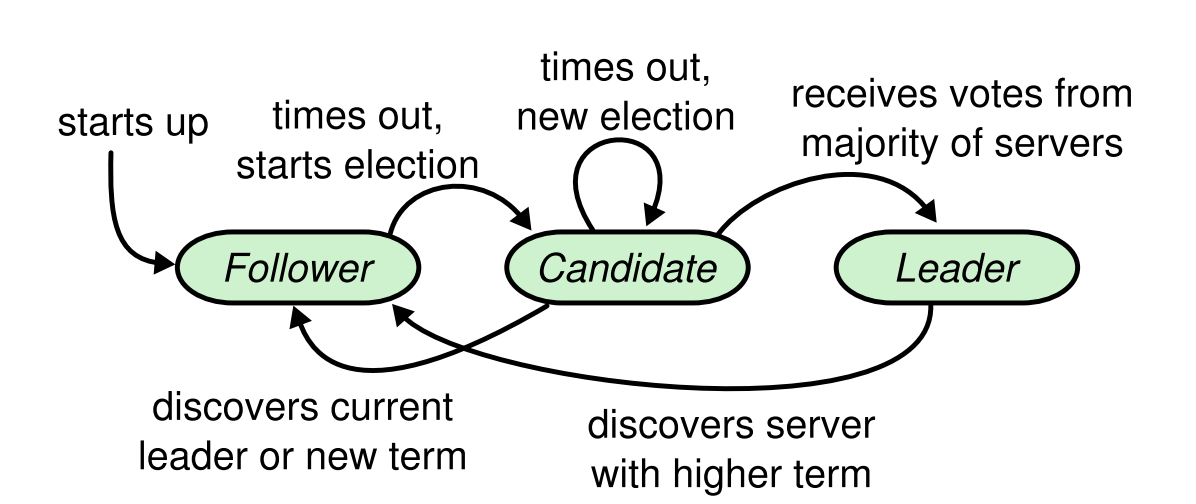
各个角色后台所需要一直运行的任务吧
Follower & Candidate & leader: 🔗
- 检测选举超时,如果超时,需要发起选举。leader 不需要检测,但是需要保持这个后台任务,因为 leader 可以转变成其它状态
- 应用 log 到上层应用,commitIndex > appliedIndex, 则需要把 [appliedIndex + 1, committedIndex] 的 log,应用到上层应用,for 2b
Leader: 🔗
- 定时发送日志复制请求(心跳是其一个特例),防止其它 server 发起选举(其它 server 收到请求, 重置选举时间)
- 更新 leader 的 commitIndex,这里需要检测新 log 是否复制到大多数机器上了,for 2b
两种 RPC 🔗
Raft 就两个 RPC,这里简单说明下它们是干什么的
RequestVote 🔗
-
触发请求的时机:
- 选举超时 (follower/candidate 在一段时间没收到 leader 的心跳了)
-
接收到请求,server 端的逻辑
- 拒绝 term 比自己小的请求
- 收到 term 比自己大的请求,更新term,转成 Follower,再往下处理
- 判断该不该给这个请求投票
- 自己在这一轮,还没有投过票
- 只给对方日志领先(包括一致)自己日志的投票(这样才能选出包括 commited 日志的 Leader)
-
收到回复后,client 逻辑
-
如果 reply 的 term 比自己 term 大,更新term,转成 Follower,直接返回
-
如果 reply 投票成功,numVote ++
-
numVote 大于一半的服务数,当选成 leader
-
AppendEntries 🔗
- 触发请求的时机
- 定时发送(只有 Leader 发送)
- 接收到请求,server 端的逻辑
- 拒绝 term 比自己小的请求
- 收到 term 比自己大的请求,更新term,转成 Follower,再往下处理
- 重置选举时间
- 对比自己的 Log 与 args 发过来 prevLog
- 如果自己的 log 数量少于 prevLogIndex,返回 FALSE
- 或者在同一位置 Index 有日志,但 term 不一致,返回 FALSE
- 截取掉比 prevLog 多的 Log
- append 新的 Log
- 根据 leader 发过来的 CommitIndex 与 自己的 LastIndex 更新自己的 commitIndex
- 收到回复,client 逻辑
- 如果 reply 的 term 比自己 term 大,更新term,转成 Follower,直接返回
- 如果收到说明复制成功,更新 nextIndex 与 matchIndex
- 如果收到复制失败,nextIndex -= 1,在下次心跳中重试
一个具体例子 🔗
如图,一个 Raft 到了现在的状态
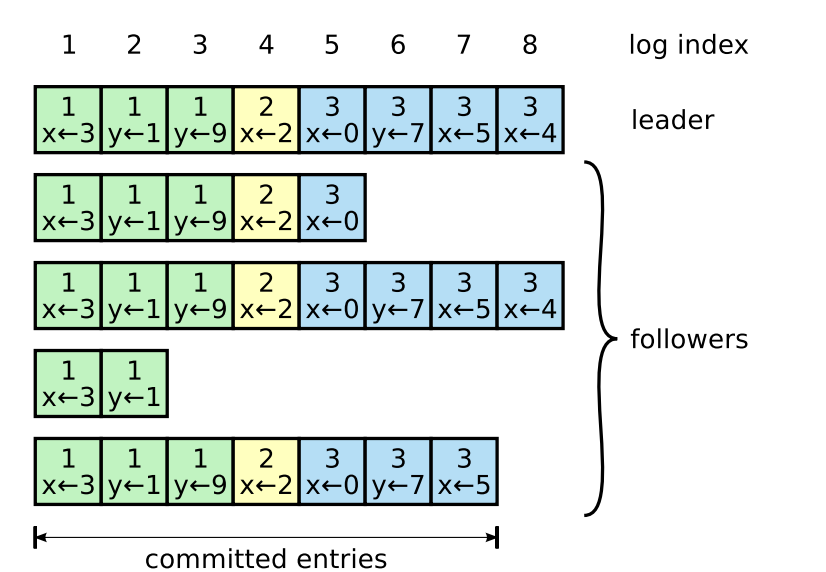
放出各个 Raft 实例中字段的值,加深对各个字段理解
| Leader0 | Follower1 | Follower2 | Follower3 | Follower4 | |
|---|---|---|---|---|---|
| currentTerm | 3 | 3(可能掉线) | 3 | 完全掉线 | 3 |
| voteFor | 0 | 0 | 0 | 3 | 0 |
| log | [1,1,1,2,3,3,3,3] | [1,1,1,2,3] | [1,1,1,2,3,3,3,3] | [1,1] | [1,1,1,2,3,3,3] |
| commitIndex(2B) | 7 | 4 | 7 | 1 | 6 |
| lastApplied(2B) | 7 | 4 | 7 | 1 | 6 |
| nextIndex | [9,6,9,3,8] | - | - | - | - |
| matchIndex | [8,5,8,2,7] | - | - | - | - |
如果 leader 此时发起心跳, AppendEntries 请求参数:
| Follower1 | Follower2 | Follower3 | Follower4 | |
|---|---|---|---|---|
| term | 3 | 3 | 3 | 3 |
| leaderID | 0 | 0 | 0 | 0 |
| prevLogIndex | 5 | 8 | 2 | 7 |
| prevLogTerm | 3 | 3 | 1 | 3 |
| entries | [3,3,3] | [] | [1,2,3,3,3,3] | [3] |
| leaderCommit | 7 | 7 | 7 | 7 |
如果 此时 leader 1 也完全掉线了,Follower 1, 2, 4 都有可能发起选举(2 也有可能,这里不讨论了),分别看一下可能发起的第一轮选举 RequestVote args
| Follower1 | Follower2 | Follower4 | |
|---|---|---|---|
| term | 4 | 4 | 4 |
| candidateID | 1 | 2 | 4 |
| lastLogIndex | 5 | 8 | 7 |
| LastLogTerm | 3 | 3 | 3 |
计时器如何实现 🔗
- 在一个协程里用死循环
- sleep 一个短的时间间隔(5ms)去检查超时时间与当前时间,如果 Now() 大于 超时时间,则说明超时了,需要进行逻辑处理
- 其它协程可以不断重置超时时间
for rf.killed() == false {
if time.Now().After(rf.loadTimeout()) {
// do ....
}
time.Sleep(5 * time.Millisecond)
}
func (rf *Raft) resetTimeout() {
rand.Seed(time.Now().UnixNano())
rf.electionTimeout = time.Now().Add(time.Millisecond*time.Duration(ElectionTimeoutMinMs + rand.Intn(ElectionTimeOutMaxMs-ElectionTimeoutMinMs+1)))
}
const (
HeartbeatMs = 100 // leader 100Ms 发起一次心跳
ElectionTimeoutMinMs = 250 // 最小的选举时间
ElectionTimeOutMaxMs = 400 // 最大的选举时间
)
个人经验与踩坑 🔗
1. Raft 实现 Log Index 从 1 开始 🔗
- Index = 0 即代表刚启动时的 Raft,还没有一条 Log,此时发起投票或者心跳,需要处理这个特殊的 log,mock 一个 term为 -1的 log 返回。
func (rf *Raft) getLog(index int) LogEntry {
if index == 0 {
return LogEntry{Term: -1}
}else {
return rf.logs[index-1]
}
}
2. 如何加锁防止 race 🔗
- Raft 结构中的变量大多数都是有竞争的,任何对 Raft 结构变量读写前请加锁
- 两个 RPC handler 都是并发的,请直接给方法加锁
- 并发开启 goroutine 读写共享变量加锁
3. 如何加锁防止死锁 🔗
- mutex 是不可重入锁
rf.mu.Lock()
loadState() // 死锁
rf.mu.Unlock()
func (rf *Raft) loadState() State {
rf.mu.Lock()
defer rf.mu.Unlock()
return rf.state
}
- 不要把 rpc 请求锁在里面,在前后分开加锁
- 不要忘记释放锁(if 中 unlock)
rf.mu.Lock()
if rf.state != Leader {
// rf.mu.Unlock() if 中的 unlock
return
}
rf.mu.Unlock()
4. 并发难以 debug,请在关键位置打 Log 🔗
- Handler 收到 RPC 请求
- 收到 RPC 回复时
- 角色身份变化时
- …
5. 两个 RPC 处理有一致的代码逻辑 🔗
如 handler 开始的一段处理逻辑一致
接收到请求,server 端的逻辑
- 拒绝 term 比自己小的请求
- 收到 term 比自己大的请求,更新term,转成 Follower,再往下处理
// RequestVote handler
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// rpc handler 通常是并发,加锁
rf.mu.Lock()
defer rf.mu.Unlock()
log.Printf("%d 在 term %d 收到了 RequestVote request %+v", rf.me, rf.currentTerm, args)
// rpc handler 通用的规则: args 中 term 比 当前小,直接返回
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
// rpc handler 通用规则: args 中的 term 比当前 server 大,当前 server 更新为 term,转成 follower
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.voteFor = -1
rf.state = Follower
}
// ...
}
如 client 端
收到回复,client 逻辑
- 如果 reply 的 term 比自己 term 大,更新term,转成 Follower,直接返回
if ok := rf.sendRequestVote(i,args, reply); !ok {
return
}
// 这些变量可能并发修改了,需要注意
rf.mu.Lock()
defer rf.mu.Unlock()
// 通用规则: reply 中 term 大于当前,转为 Follower
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.voteFor = -1
rf.toFollower()
return
}
// ....
6. 尽量使用大锁,不要考虑性能 🔗
7. Logs 复制请用深拷贝,不然很可能有并发 race 问题 🔗
8. RPC 请求前后请 double check: 🔗
- 当前角色是否还需要进行这个动作,
- 当前 term 是否还需要处理这个 回复
- 回复的 term 是否与发起的 term 一致
具体实现 🔗
1. 填写 Raft 和两个 RPC 结构 🔗
根据论文依葫芦画瓢就行,后期根据自己需要再加,raft 结构已放过,这里放一下 RPC 的
type AppendEntriesArgs struct {
Term int
LeaderID int
PrevLogIndex int
PrevLogTerm int
Entries []LogEntry
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
}
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
}
// AppendEntries handler
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// ...
}
type RequestVoteArgs struct {
Term int
CandidateID int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
Term int
VoteGranted bool
}
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
// RequestVote handler
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
}
2. 启动 Raft,初始化 🔗
- 一些状态的初始赋值,如刚启动的 raft 角色是 follower
- 启动检测选举超时的协程
- 对于 2B 还需要在定期应用 commited 的 log 到上层应用
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
rf.applyCh = applyCh
// Your initialization code here (2A, 2B, 2C).
rf.toFollower()
rf.voteFor = -1
rf.resetTimeout()
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
go rf.applyMsgToUpper() // for 2B
return rf
}
3. leader 选举的逻辑 🔗
上面的初始化中,启动了 go rf.ticker()的协程,现在需要实现 leader 选举这一部分逻辑
-
一个死循环,计时器的实现
-
如果其角色不是 leader 并且过了选举时间,发起选举
-
成为 candiate, 给自己投一票
-
并发对其它所有 Raft 实例发起请求
-
由于 RPC 消息延迟比较大,因此需要 double check,当前实例的状态是否能投票
-
计数得到票数,票数超过一半,当选为 Leader
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) ticker() {
for rf.killed() == false {
// 状态不是 Leader, 并且已经过了选举时间,需要发起选举
if rf.loadState() != Leader && time.Now().After(rf.loadTimeout()) {
// 1. 成为 candidate
rf.mu.Lock()
rf.toCandidate()
// 2. 发起投票
numVote := 1
// 所有 requestVote 的请求参数一致
args := &RequestVoteArgs{
Term: rf.currentTerm,
CandidateID: rf.me,
LastLogIndex: rf.getLastIndex(),
LastLogTerm: rf.getLog(rf.getLastIndex()).Term,
}
rf.mu.Unlock()
for i, _ := range rf.peers {
if i == rf.me {
continue
}
go func(i int) {
reply := &RequestVoteReply{}
// 不能以不是 Candidate 的身份发送投票
if rf.loadState() != Candidate {
return
}
// rpc 请求
if ok := rf.sendRequestVote(i,args, reply); !ok {
return
}
// 这些变量可能并发修改了,需要注意
rf.mu.Lock()
defer rf.mu.Unlock()
// 通用规则: reply 中 term 大于当前,转为 Follower
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.voteFor = -1
rf.toFollower()
return
}
// double check,因为有可能发起新一轮选举了,才收到这个消息
if rf.state != Candidate || reply.Term != rf.currentTerm || reply.Term != args.Term {
return
}
// 投票
if reply.VoteGranted {
numVote ++
log.Printf("%d 在 term %d 收到了 %d 的投票,现在票数 %d", rf.me, rf.currentTerm, i,numVote)
}
// 成为 Leader
if numVote > len(rf.peers)/2 {
rf.toLeader()
}
}(i)
}
}
time.Sleep(5 * time.Millisecond)
}
}
与角色转换的方法:
func (rf *Raft) toFollower() {
log.Printf("%d 在term %d 成为 follower", rf.me, rf.currentTerm)
rf.state = Follower
}
func (rf *Raft) toCandidate() {
rf.currentTerm ++
log.Printf("%d 在 term %d 发起了投票", rf.me,rf.currentTerm)
rf.voteFor = rf.me
rf.state = Candidate
rf.resetTimeout()
}
与 log 的有关的工具方法
func (rf *Raft) getLastIndex() int {
return len(rf.logs)
}
func (rf *Raft) getLog(index int) LogEntry {
if index == 0 {
return LogEntry{Term: -1}
}else {
return rf.logs[index-1]
}
}
// 包括: start 和 end, 深拷贝,不然极限情况下会有 race 的 bug
func (rf *Raft) subLog(start int, end int) []LogEntry {
if start == -1 {
return append([]LogEntry{}, rf.logs[:end]...)
}else if end == -1{
return append([]LogEntry{}, rf.logs[start-1:]...)
}else {
return append([]LogEntry{}, rf.logs[start-1: end]...)
}
}
4. RequestVote server 端的逻辑 🔗
在前面已经描述大致逻辑了,前面一大堆都是共有逻辑,20 行开始才是真正处理逻辑,这里直接看代码
// RequestVote handler
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// rpc handler 通常是并发,加锁
rf.mu.Lock()
defer rf.mu.Unlock()
log.Printf("%d 在 term %d 收到了 RequestVote request %+v", rf.me, rf.currentTerm, args)
// rpc handler 通用的规则: args 中 term 比 当前小,直接返回
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
// rpc handler 通用规则: args 中的 term 比当前 server 大,当前 server 更新为 term,转成 follower
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.voteFor = -1
rf.state = Follower
}
reply.Term = rf.currentTerm
lastIndex := rf.getLastIndex()
// 发起投票的 candidate 要比当前有更新的 log
isNewer := true
if rf.getLog(lastIndex).Term > args.LastLogTerm {
isNewer = false
}else if rf.getLog(lastIndex).Term == args.LastLogTerm {
if lastIndex > args.LastLogIndex {
isNewer = false
}
}
if (rf.voteFor == -1 || rf.voteFor == args.CandidateID) && isNewer {
log.Printf("%d 在 term %d 给 %d 投票", rf.me,rf.currentTerm,args.CandidateID)
rf.voteFor = args.CandidateID
reply.VoteGranted = true
return
}
}
5. 当选为 Leader 🔗
- 初始化 nextIndex 与 matchIndex 数组
- 开启心跳后台协程
- 开启后台更新 commitIndex 协程
func (rf *Raft) toLeader() {
log.Printf("%d 在term %d 成为了 leader", rf.me,rf.currentTerm)
rf.state = Leader
// 成为 leader 要初始化 nextIndex matchIndex 数组
rf.nextIndex = make([]int, len(rf.peers))
rf.matchIndex = make([]int, len(rf.peers))
for i := 0; i < len(rf.peers); i ++ {
rf.nextIndex[i] = rf.getLastIndex() + 1
}
go rf.heartbeat()
go rf.updateCommitIndex() // for 2b
}
6. leader 发起心跳(日志复制)RPC 🔗
定期发起心跳, 角色不是 leader,退出这个协程
func (rf *Raft) heartbeat() {
for rf.killed() == false {
rf.mu.Lock()
log.Printf("%d 在 term %d 触发心跳, state: %d, nextIndex: %+v", rf.me, rf.currentTerm, rf.state, rf.nextIndex) // 共享变量访问 要加锁
if rf.state != Leader {
rf.mu.Unlock()
return
}
rf.mu.Unlock()
rf.sendAppendLogsToAll()
time.Sleep(HeartbeatMs * time.Millisecond)
}
把心跳(复制日志)的 RPC 并发发送到每个 RPC 实例,逻辑在上文中提到,这里直接看代码理解
func (rf *Raft) sendAppendLogsToAll() {
//log.Printf("%d 在 term %d 发起同步", rf.me, rf.currentTerm) // 这里 CurrentTerm 没加锁,可能会有 race
for i := range rf.peers {
if i == rf.me {
continue
}
go func(i int) {
rf.mu.Lock()
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderID: rf.me,
PrevLogIndex: rf.nextIndex[i] - 1,
PrevLogTerm: rf.getLog(rf.nextIndex[i] - 1).Term,
Entries: rf.subLog(rf.nextIndex[i], -1),
LeaderCommit: rf.commitIndex,
}
reply := &AppendEntriesReply{}
// 这个检查是因为当一个协程收到比当前 term 大的 reply,会转变成 follower. 后面协程不应该再以 leader 身份发送同步信息
if rf.state != Leader {
rf.mu.Unlock()
return
}
rf.mu.Unlock()
if ok := rf.sendAppendEntries(i, args, reply); !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
log.Printf("%d 在 term %d 收到 %d 的AppendEntries reply %+v", rf.me, rf.currentTerm, i,reply)
// 所有 server 的规则
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.voteFor = -1
rf.toFollower()
return
}
// double check
if rf.state != Leader || reply.Term != rf.currentTerm || reply.Term != args.Term {
return
}
if reply.Success {
// rf.nextIndex[i] += len(args.Entries) 走过的一个 bug
// rf.matchIndex[i] = rf.nextIndex[i] - 1
rf.nextIndex[i] = args.PrevLogIndex + len(args.Entries) + 1
rf.matchIndex[i] = args.PrevLogIndex + len(args.Entries)
}else {
// 实际上把重试的机制推到了下次心跳
rf.nextIndex[i] = args.PrevLogIndex
}
}(i)
}
}
7. AppendEntries server 处理逻辑 🔗
这里处理的准则,各个 server 之间 prevLogIndex 之前的日志保持一致,才能增加新的 log。
-
少 log 的补上 (重试:下一次 prevLogIndex - 1)
-
不一致的删掉
// AppendEntries handler
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// rpc handler 通常是并发,加锁
rf.mu.Lock()
defer rf.mu.Unlock()
log.Printf("%d 在 term %d 收到 %d 的 AppendEntries request %+v", rf.me, rf.currentTerm, args.LeaderID, args)
// rpc handler 通用的规则: args 中 term 比 当前小,直接返回
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
// rpc handler 通用规则: args 中的 term 比当前 server 大,当前 server 更新为 term,转成 follower
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.voteFor = -1
rf.toFollower()
}
rf.resetTimeout()
reply.Term = rf.currentTerm
// 调用者需要减少 PrevLogIndex,重试
if rf.getLastIndex() < args.PrevLogIndex || rf.getLog(args.PrevLogIndex).Term != args.PrevLogTerm {
return
}
reply.Success = true
// 删除比 leader 多的 log
rf.logs = rf.subLog(-1, args.PrevLogIndex)
// 新增的 Entries 放入
rf.logs = append(rf.logs, args.Entries...)
// 更新成 Follower 的 commit
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(args.LeaderCommit, rf.getLastIndex())
}
}
到这一步 2a 的逻辑已完成,下面是处理 2b 所需要的。
8. leader 更新 commitIndex 🔗
定期去检查 commiteIndex + 1 的 Log 是否复制到大多数机器上
func (rf *Raft) updateCommitIndex() {
for rf.killed() == false {
rf.mu.Lock()
for n := rf.getLastIndex(); n >= rf.commitIndex + 1; n -- {
// 论文中提到只能提交当前任期的日志,但我暂时感觉有点无意义,因为这样不还是顺带把任期小的提交了
if rf.getLog(n).Term != rf.currentTerm {
break
}
count := 0
for i := range rf.matchIndex {
if rf.matchIndex[i] >= n {
count ++
}
if count > len(rf.peers) / 2 {
rf.commitIndex = n
break
}
}
}
rf.mu.Unlock()
time.Sleep(5*time.Microsecond)
}
}
10. 把消息应用到上层 🔗
也是定期去检查是否存在已 commited 的 log 没有应用到上层应用
func (rf *Raft) applyMsgToUpper() {
for rf.killed() == false {
rf.mu.Lock()
if rf.commitIndex > rf.lastApplied {
rf.lastApplied ++
msg := ApplyMsg{
CommandValid: true,
Command: rf.getLog(rf.lastApplied).Command,
CommandIndex: rf.lastApplied,
}
rf.applyCh <- msg
log.Printf("%d 在 term %d 往上层状态机成功发送 Msg %+v", rf.me, rf.currentTerm, msg)
}
rf.mu.Unlock()
time.Sleep(10*time.Millisecond)
}
}
11. 接受上层应用消息 🔗
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
term, isLeader := rf.currentTerm, rf.state == Leader
if !isLeader {
return -1, term, isLeader
}
rf.logs = append(rf.logs, LogEntry{
Command: command,
Term: term,
})
rf.nextIndex[rf.me] = rf.getLastIndex() + 1
rf.matchIndex[rf.me] = rf.getLastIndex()
return rf.getLastIndex(), term, isLeader
}
总结 🔗
上述就是我 Raft 2a 2b 部分的实现逻辑了,上述涉及代码可能不太齐全,不过相信你能够补齐。
在测试中请多跑几次脚本(10 次?),一两次无 bug 出现可能只是运气好
个人测试上述的实现,在 2a 2b 测试样例中能完美运行,如果你发现上述实现存在 bug,请评论告知我。