从 Golang 中的字符串出发
-
len("ab你好")返回多少 -
已经存在用下标遍历字符串的方式,为什么还要有
for _,ch range str,有什么区别
从 ASCII 字符编码到 UTF-8 🔗
起点: ASCII 码 🔗
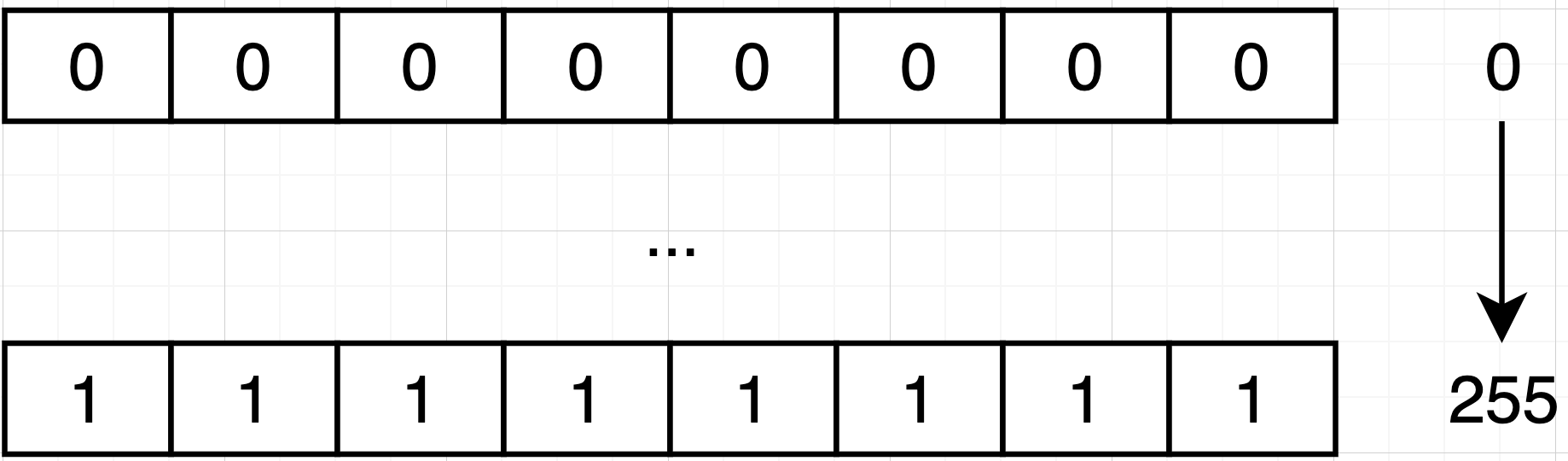
首先我们知道在计算机的世界中,一切数据都是以字节流的形式存在。例如下图,一个字节(8 个 bit)可以表示从 0 - 255 之间的整数。
但是我如果想表示一个字符呢?
字符定义:
在电脑和电信领域中,字符(Character)是一个信息单位。对使用字母系统或音节文字等自然语言,它大约对应为一个音位、类音位的单位或符号。简单来讲就是一个汉字、假名、韩文字……,或是一个英文、其他西方语言的字母。字符的例子有:字母、数字系统或标点符号。
此时需要一个字符与整数之间的映射关系。例如,用整数 97 -> a。你传入一个整数,并且指明这个整数是字符类型,那么计算机就给你显示成字符
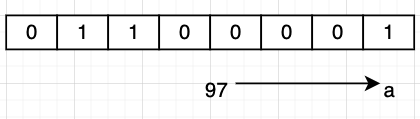
这时候最通用的 ASCII (American Standard Code for Information Interchange,美国信息交换标准代码) 在 1963 年由美国国家标准协会提出。
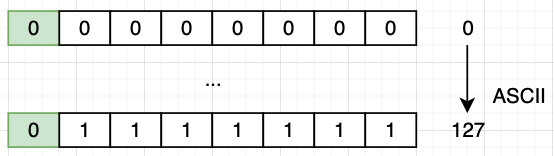
最初版 ASCII 编码使用一个字节中的 7 个 bit 位 (整数 0-127)定义了整数到 128 个字符的映射关系。 ASCII 定义的 128 个字符与其编码方式如下图所示。
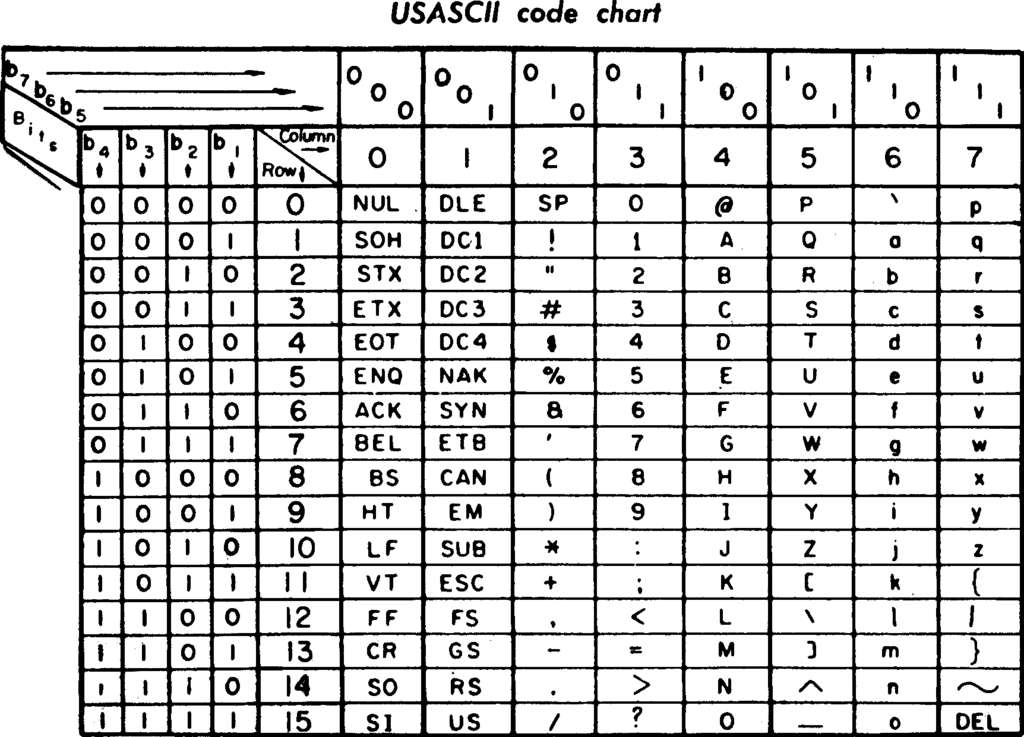
编码范围 🔗
十进制: 0-127
字节形式:
ASCII 意义 🔗
包含了使用最广泛的控制字符、数字符号、英文字母、英文符号,作为鼻祖,成为计算机编码系统的基础,以后出现的各种字符编码基本都要兼容它
缺点 🔗
只能表示一些基本英文字母、阿拉伯数字和英式标点符号。所以基本只适用于英语语系的国家
字符集与字符编码的区别 🔗
在这里先补充下字符集与字符编码定义的区别,再继续介绍
字符集:字符的集合,并为其中的每个字符分配了唯一的编号(码点),例如可以把所有英文字符定义为一种集合,也可以把所有中文字符定义为一种字符集。
字符编码:字符集映射成字节流的方式,可以直接把码点直接存储在计算机中,也可以做一次转换。
在最早期,一种字符集只有一种编码方式,直接使用它们码点数字存储在计算机。如 ASCII 码,它是一种字符集也是一种字符编码,所以叫法比较乱。
直到 Unicode 出现,这两者之间的区别才比较清晰。如 Unicode 是一种字符集,每一个字符都会预先分配一个编号。而 utf-8、utf-16、utf-32 都是其中的一种编码方式
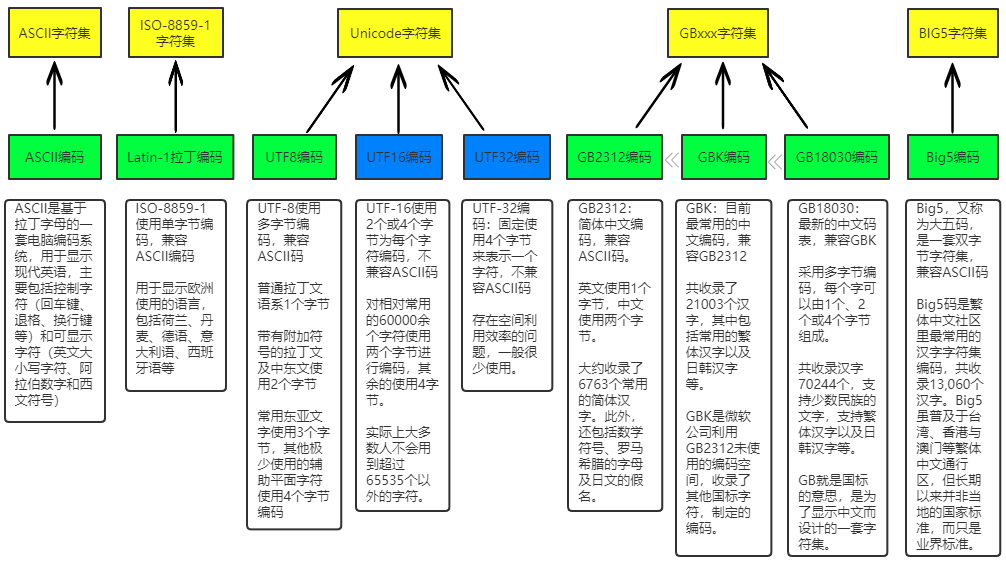
野蛮发展时期 🔗
显然 ASCII 字符集包括的128 个字符不能满足广大人民群众的需求,于是字符集的扩充陷入到一阵野蛮发展的时期
EASCII 🔗
ASCII 出来后,最先感到不适应的是欧洲地区,欧洲一些地区也比较发达,但所使用的语言不是英语,如法语之类的,其语言的一些字符在电脑中无法表示。
于是扩展 ASCII (EASCII) 出现了,由于 ASCII 码只使用了一个字节中的 7 个 bit,扩展 ASCII 就是利用了剩下的最高 bit (128 - 255) 扩展出了 128 个字符使用。EASCII 拓展的字符在字节里最高位都是 1.
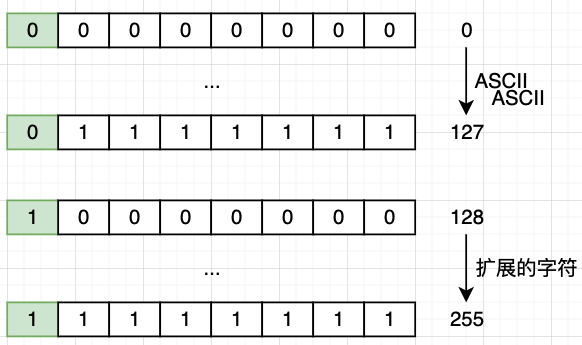
这扩展的 128 字符如下图,如要包括表格符号、计算符号、希腊字母和特殊的拉丁符号
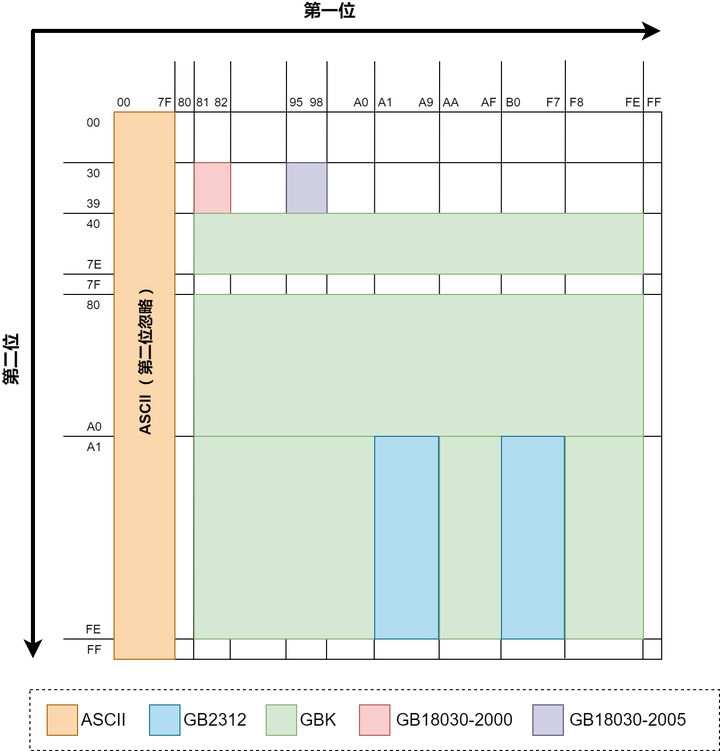
GB2313、BIG5、GBK 与 GB18030 中文字符集的发展 🔗
时代在发展,当计算机渐渐在东亚流行后,计算机无法表示当地字符,东亚人民感受到极大的不便
GB 2313 🔗
GB2313 是中国国家标准简体中文字符集,由中国国家标准总局于1980年发布,支持的字符
-
6763 个常用汉字
-
682 个其它字符
编码方式
-
兼容 ASCII 字符
-
新增汉字和其它字符使用两个字节编码
如何在字节流中区分 ASCII 字符与 GB2312 支持的字符
-
最高位 0 的字节是 ASCII 字符
-
最高位 1 的字节 + 后续的一个字节组成 GB 2312 支持的字符
理论中的编码范围如下,实际上总共需要表示 7445 多个字符,只使用了一部分空间。
BIG5 🔗
由于 GB2312 不包括繁体字符,台湾同胞们不乐意了
BIG5: BIG-5 码是通行于台湾、香港地区的一个繁体字编码方案。使用2个字节表示,表示13053 个汉字
GBK 🔗
中国也有使用繁体字的需求,于是 GBK 增加了对繁体字的支持,在 1995 年被提出。兼容 GB2312,还是使用 2 个字节表示,可表示 21886 个字符
GB18030 🔗
随着计算机逐渐深入人民生活,发现有相当部分的人的名字包括生僻字,无法在计算机中表示。
GB18030 在 2005 年有中国国家标准化管理委员会提出。
- 支持中国国内少数民族的文字
- 汉字收录范围包含繁体汉字以及日韩汉字
编码方式
-
1, 2, 4 个字节的变长编码
-
一个字节兼容 ASCII 编码
-
两个字节兼容 GBK 编码
-
四个字节支持新增的字符
终点: Unicode 字符集 🔗
上述的的一系列字符集只是在中国这一块区域出现的,而世界上还有这么多国家,这么多文化、文字。
-
字符集与字符编码数量爆炸和不兼容,使得开发人员痛苦,、
-
并且日常使用中人们经常选择错误的编码方式打开文本导致乱码
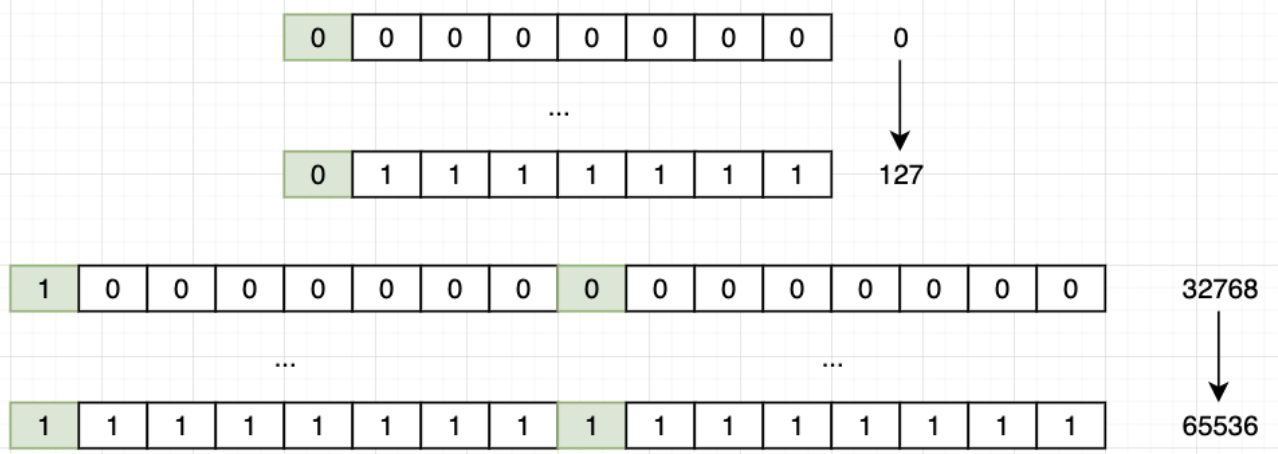
Unicode 全称 Unicode Character Set,是国际组织制定的可以容纳世界上所有文字和符号的集合
Unicode 字符集目前包括两个主要版本
-
2 个字节的版本,能表示 65536 个字符,目前普遍使用
-
4 个字节的版本,理论能表示十亿级别数量的字符,实际包括了一百多万个字符,目前使用还较少
上面说的字节只是各个字符的 unicode 码点(编号),并不是其在计算机中存储实际所占用多少个字节,在计算机中实际存储决定于字符编码,UTF(Unicode Transformation Format)
UTF-32 🔗
UTF-32 是最简单的编码方式,每个码点使用四个字节表示,字节内容一一对应码点,即计算机中存储就是定义的码点
U+0000 = 0x0000 0000
u+597D = 0x0000 597D
优点
- 定长编码,转换规则简单直观
缺点
-
内存占用大,如果一篇纯粹由 ASCII 字符组成的文本,UTF-32 占用空间大四倍
-
不兼容 ASCII
UTF-16 🔗
UTF-16: 介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储
-
对于 Unicode 编号在 0 ~ FFFF,直接存储 Unicode 编号
-
对于 Unicode 编号在 10000 ~10FFFF,使用四个字节存储

UTF-16 如何区分是 2 个字节还是 4 个字节组成一个字符
- U+D800 到 U+DFFF 在 unicode 中不对应任何字符,UTF-16 用这个区域的码点说明这两个字节和后面的两个字节共同组成一个字符
优点
-
相对 UTF-32 节省空间
-
转换相对简单
-
文化上相对公平
缺点
-
不兼容 ASCII
-
UTF-16 存在大小端字节序问题
UTF-8 🔗
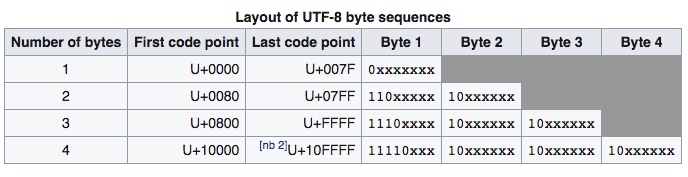
UTF-8: 变长字符编码方式,用一至六个字节对 Unicode 字符集中的所有有效码点进行编码,目前实际上最多使用到了 4 个字节
-
1 个字节:ASCII 字符
-
2 个字节: 拉丁字母、希腊文 、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等
-
3 个字节:汉字和其它语言字符
-
4 个字节:几乎没有用到
UTF-8 如何区分变长字节
优点
-
兼容 ASCII
-
对西文编码优势比较大
-
无字节序大小端的问题
缺点
-
文化上不平衡,汉字需要 3 个字节,英文只需要 1 个字节存储
-
变长字节带来的效率问题,如何计算字符数?
目前,UTF-8 编码由于其优势,已经在互联网上占据压倒式优势了,因此 Golang 字符串的实现基于 UTF-8 也是符合潮流
字符编码常见问题 🔗
- MySQL 中 utf-8mb4 是什么
答:MySQL 中原先的 utf-8 只支持 3 个字节的编码。完整的 utf-8 理论上支持最多 6 个字节(目前最多四个字节)。utf-mb4 指的是支持最多 4 个字节的编码,主要是一些 emoji 符号。
-
为什么 notepad 上字符编码很多都看不懂
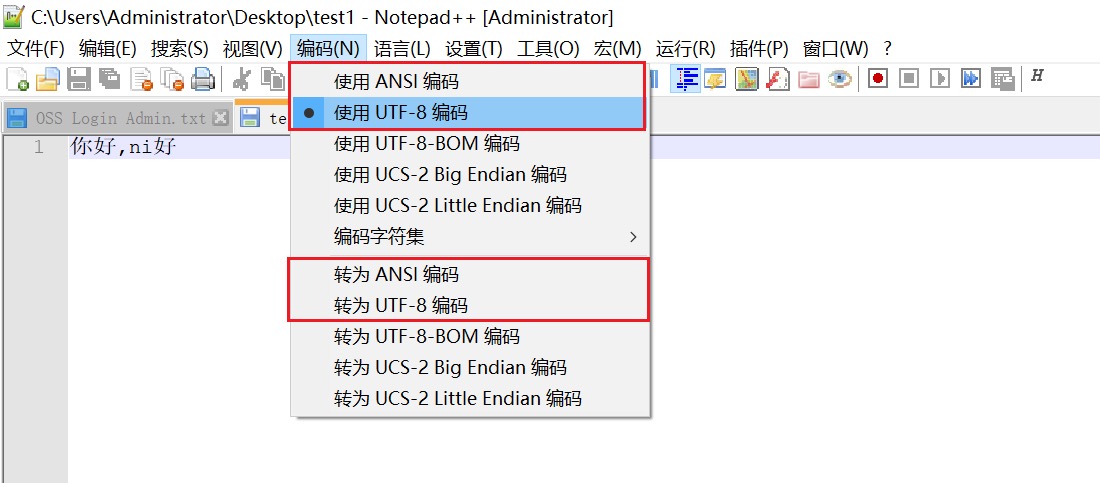
ANSI,由微软提出
-
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;
-
在繁体中文Windows操作系统中,ANSI编码代表Big5;
-
在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码
UCS2,国际标准化组织(ISO)提出的统一码,后面和 UTF-16 合并了,现在基本等于 UTF-16,UCS4 与 UTF-32 同理
BigEndian、Little Endian,字节序大小端
BOM: 微软提出在所有的 Unicode 文件开头加入标识,来识别所使用的编码和字节顺序
插入到以UTF-8、UTF16 或 UTF-32 编码 Unicode 文件开头的特殊标记,用来识别Unicode文件的编码类型。对于UTF-8来说,BOM并不是必须的